[Oct.-2016-NEW]High Quality 70-467 Dumps PDF and VCE 189Q&As Free Share[NQ26-NQ33]
2016/10 Latest Microsoft 70-467: Designing Business Intelligence Solutions with Microsoft SQL Server Exam Questions Updated Today!
Free Instant Download 70-467 Exam Dumps (PDF & VCE) 189Q&As from Braindump2go.com Today! 100% Real Exam Questions! 100% Exam Pass Guaranteed!
1.|2016/10 New 70-467 Exam Dumps (PDF & VCE) 189Q&As Download:
http://www.braindump2go.com/70-467.html
2.|70-467 Exam Questions & Answers:
https://drive.google.com/folderview?id=0B9YP8B9sF_gNM1Z3aG9yTjZUYW8&usp=sharing QUESTION 26
You are developing the database schema for a SQL Server Analysis Services (SSAS) BI Semantic Model (BISM).
The BISM will be based on the schema displayed in the following graphic.
You have the following requirements:
- Ensure that queries of the data model correctly display average student age by class and average class level by student.
- Minimize development effort.
You need to design the data model.
What should you do? (More than one answer choice may achieve the goal. Select the BEST answer.)
 A. Create a multidimensional project and define measures and a reference relationship.
B. Create a tabular project and define calculated columns.
C. Create a multidimensional project and define measures and a many-to-many dimensional
relationship.
D. Create a tabular project and define measures. Answer: C QUESTION 27
Drag and Drop Questions
You are designing a self-service business intelligence and reporting environment.
Business analysts will create and publish PowerPivot for Microsoft Excel workbooks and create reports by using SQL Server Reporting Services (SSRS) and Power View.
When the data models become more complex and the data volume increases, the data models will be replaced by IT-hosted server-based models.
You have the following requirements:
- Maintain the self-service nature of the reporting environment.
- Reuse existing reports.
- Add calculated columns to the data models.
You need to create a strategy for implementing this process.
What should you do? To answer, drag the appropriate term or terms to the correct location or locations in the answer area. (Answer choices may be used once, more than once, or not all.)

Answer:
 QUESTION 28
You are modifying a star schema data mart that feeds order data from a SQL Azure database into a SQL Server Analysis Services (SSAS) cube.
The data mart contains two large tables that include flags and indicators for some orders.
There are 100 different flag columns, each with 10 different indicator values.
Some flags reuse indicators. The tables both have a granularity that matches the fact table.
You have the following requirements:
- Allow users to slice data by all flags and indicators.
- Modify the date dimension table to include a surrogate key of a numeric data type and add the surrogate key to the fact table.
- Use the most efficient design strategy for cube processing and queries.
You need to modify the schema.
What should you do? (More than one answer choice may achieve the goal. Select the BEST answer.) A. Define the surrogate key as an INT data type.
Combine the distinct flag/indicator combinations into a single dimension.
B. Define the surrogate key as an INT data type.
Create a single fact dimension in each table for its flags and indicators.
C. Define the surrogate key as a BIGINT data type.
Combine the distinct flag/indicator combinations into a single dimension.
D. Define the surrogate key as a BIGINT data type.
Create a single fact dimension in each table for its flags and indicators. Answer: A QUESTION 29
You are defining a named set by using Multidimensional Expressions (MDX) in a sales cube.
The cube includes a Product dimension that contains a Category hierarchy and a Color attribute hierarchy.
You need to return only the blue products in the Category hierarchy.
Which set should you use? (More than one answer choice may achieve the goal. Select the BEST answer.)
 A. Option A
B. Option B
C. Option C
D. Option D Answer: C QUESTION 30
An existing cube dimension that has 30 attribute hierarchies is performing very poorly.
You have the following requirements:
- Implement drill-down browsing.
- Reduce the number of attribute hierarchies but ensure that the information contained within them is available to users on demand.
- Optimize performance.
You need to redesign the cube dimension to meet the requirements.
What should you do? (More than one answer choice may achieve the goal. Select the BEST answer.) A. set the AggregateFunction property to Sum on all measures. Use the SCOPE statement in a
Multidimensional Expressions (MDX) calculation to tune the aggregation types.
B. Set the AttributeHierarchyOptimizedState property to FullyOptimized on the attribute
hierarchies.
C. Create user-defined hierarchies. For the attributes sourced by the levels of the user-defined
hierarchies, set the RelationshipType property to Rigid. Run incremental processing.
D. Remove as many attribute hierarchies as possible from the dimension.
Reintroduce the information in the attribute hierarchies as properties.
Implement natural hierarchies and set the AttributeHierarchyVisible property to False for
attributes used as levels in the natural hierarchies. Answer: D QUESTION 31
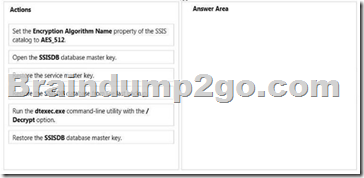
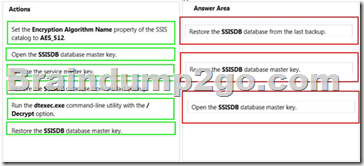
You are the administrator of a SQL Server Integration Services (SSIS) catalog.
You have access to the original password that was used to create the SSIS catalog.
A full database backup of the SSISDB database on the production server is made each day.
The server used for disaster recovery has an operational SSIS catalog.
The production server that hosts the SSISDB database fails.
Sensitive data that is encrypted in the SSISDB database must not be lost.
You need to restore the production SSIS catalog to the disaster recovery server.
Which three steps should you perform in sequence? (To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.)
Answer:
 QUESTION 32
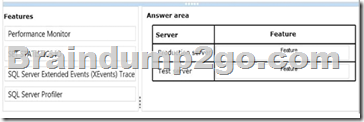
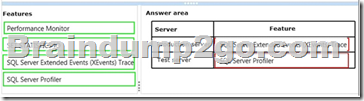
Several reports are based on the same SQL Server Analysis Services (SSAS) cube.
Each report has several datasets defined with complex Multidimensional Expressions (MDX) queries.
The company maintains separate development, test and production environments.
The reports are running slowly.
You plan to analyze report performance.
You have the following requirements:
- Monitor query statistics on the production server with as little server overhead as possible.
- Gather, replay, and analyze statistics on the test server with as little administrative effort as possible.
- Identify the longest-running queries on both servers.
- Document statistics on disk reads on both servers.
You need to gather statistics and meet the requirements.
Which features should you use? To answer, drag the appropriate feature or features to the correct location or locations in the answer area. (Use only features that apply.)
Answer:
 QUESTION 33
You are designing an extract, transform, load (ETL) process for loading data from a SQL Azure database into a large fact table in a data warehouse each day with the prior day's sales data.
The ETL process for the fact table must meet the following requirements:
- Load new data in the shortest possible time.
- Remove data that is more than 36 months old.
- Minimize record locking.
- Minimize impact on the transaction log.
You need to design an ETL process that meets the requirements.
What should you do? (More than one answer choice may achieve the goal. Select the BEST answer.) A. Partition the fact table by date.
Insert new data directly into the fact table and delete old data directly from the fact table.
B. Partition the fact table by customer.
Use partition switching both to remove old data and to load new data into each partition.
C. Partition the fact table by date.
Use partition switching and staging tables both to remove old data and to load new data.
D. Partition the fact table by date.
Use partition switching and a staging table to remove old data.
Insert new data directly into the fact table. Answer: C
!!!RECOMMEND!!! 1.|2016/10 New 70-467 Exam Dumps (PDF & VCE) 189Q&As Download:
http://www.braindump2go.com/70-467.html
2.|70-467 Exam Questions & Answers:
https://drive.google.com/folderview?id=0B9YP8B9sF_gNM1Z3aG9yTjZUYW8&usp=sharing
|