[2016-Oct.-NEW]100% Real 70-470 Braindumps 283Q&As Free Download in Braindump2go[NQ17-NQ22]
2016/10 New Microsoft 70-470: Recertification for MCSE: Business Intelligence Exam Questions Updated Today!
Free Instant Download 70-470 Exam Dumps (PDF & VCE) 283Q&As from Braindump2go.com Today! 100% Real Exam Questions! 100% Exam Pass Guaranteed!
1.|2016/10 70-470 Exam Dumps (PDF & VCE) 283Q&As Download:
http://www.braindump2go.com/70-470.html
2.|2016/10 70-470 Exam Questions & Answers:
https://drive.google.com/folderview?id=0B9YP8B9sF_gNcERjZVFoYkdjTk0&usp=sharing QUESTION 17
You are designing a SQL Server Integration Services (SSIS) solution.
The solution will contain an SSIS project that includes several SSIS packages.
Each SSIS package will define the same connection managers and variables.
You have the following requirements:
- Ensure that the deployment model supports changing the content of connection strings by using parameters at execution time.
- Ensure that the deployment model automatically starts from calls to the catalog.start_execution stored procedure in the SSISDB database.
- Maximize performance at execution time.
- Minimize development effort.
You need to design a solution that meets the requirements.
What should you do? (More than one answer choice may achieve the goal. Select the BEST answer.) A. Use a project deployment model.
Modify connection manager properties to use project parameters.
Ensure that the SSISDB database is created.
B. Use a project deployment model.
Configure connections in an XML configuration file referenced by an environment variable
that corresponds to the SQL Server environment of each SSIS package.
C. Use a package deployment model.
Use a SQL Server package configuration with a common filter.
Change the contents of the SSIS Configurations table at runtime.
D. Use a package deployment model.
Save each SSIS package to a file share that can be accessed from all environments. Answer: A QUESTION 18
Drag and Drop Questions
You are creating a SQL Server Integration Services (SSIS) package to populate a fact table from a source table.
The fact table and source table are located in a SQL Azure database.
The source table has a price field and a tax field.
The OLE DB source uses the data access mode of Table.
You have the following requirements:
- The fact table must populate a column named TotalCost that computes the sum of the price and tax columns.
- Before the sum is calculated, any records that have a price of zero must be discarded.
You need to create the SSIS package in SQL Server Data Tools.
In what sequence should you order four of the listed components for the data flow task? (To answer, move the appropriate components from the list of components to the answer area and arrange them in the correct order.)

Answer:
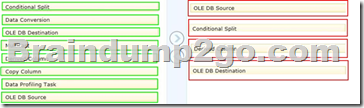
Explanation:
- You configure a Data Flow task by adding components to the Data Flow tab. SSIS supports three types of data flow components:
Sources: Where the data comes from
Transformations: How you can modify the data
Destinations: Where you want to put the data
- Creating a data flow includes the following steps:
- Adding one or more sources to extract data from files and databases, and add connection managers to connect to the sources.
- Adding the transformations that meet the business requirements of the package. A data flow is not required to include transformations.
Some transformations require a connection manager. For example, the Lookup transformation uses a connection manager to connect to the database that contains the lookup data.
- Connecting data flow components by connecting the output of sources and transformations to the input of transformations and destinations.
- Adding one or more destinations to load data into data stores such as files and databases, and adding connection managers to connect to the data sources.
- Configuring error outputs on components to handle problems. At run time, row-level errors may occur when data flow components convert data, perform a lookup, or evaluate expressions.
For example, a data column with a string value cannot be converted to an integer, or an expression tries to divide by zero. Both operations cause errors, and the rows that contain the errors can be processed separately using an error flow.
- Include annotations to make the data flow self-documenting.
- The capabilities of transformations vary broadly. Transformations can perform tasks such as updating, summarizing, cleaning, merging, and distributing data. You can modify values in columns, look up values in tables, clean data, and aggregate column values.
- The Data Flow task encapsulates the data flow engine that moves data between sources and destinations, and lets the user transform, clean, and modify data as it is moved. Addition of a Data Flow task to a package control flow makes it possible for the package to extract, transform, and load data.
A data flow consists of at least one data flow component, but it is typically a set of connected data flow components: sources that extract data; transformations that modify, route, or summarize data; and destinations that load data. QUESTION 19
Drag and Drop Questions
You are designing a SQL Server Integration Services (SSIS) package to execute 12 Transact-SQL (T-SQL) statements on a SQL Azure database.
The T-SQL statements may be executed in any order.
The T-SQL statements have unpredictable execution times.
You have the following requirements:
- The package must maximize parallel processing of the T-SQL statements.
- After all the T-SQL statements have completed, a Send Mail task must notify administrators.
You need to design the SSIS package.
Which three actions should you perform in sequence? (To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.)
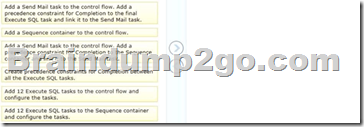
Answer:
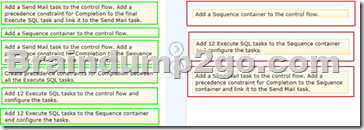
Explanation:
Box 1: Add a Sequence container to the control flow.
Box 2: Add 12 Execute SQL tasks to the Sequence container and configure the tasks.
Box 3: Add a Send mail task to the control flow. Add a precedence constraint for Completion to the to the Sequence container and link it to the Send Mail task.
Note:
The Sequence container defines a control flow that is a subset of the package control flow. Sequence containers group the package into multiple separate control flows, each containing one or more tasks and containers that run within the overall package control flow.
Reference: Sequence Container QUESTION 20
Hotspot Questions
You are configuring the partition storage settings for a SQL Server Analysis Services (SSAS) cube.
The partition storage must meet the following requirements:
- Optimize the storage of source data and aggregations in the cube.
- Use proactive caching.
- Drop cached data that is more than 30 minutes old.
- Update the cache when data changes, with a silence interval of 10 seconds.
You need to select the partition storage setting.
Which setting should you select? To answer, select the appropriate setting in the answer area.
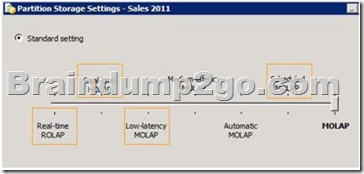
Answer:
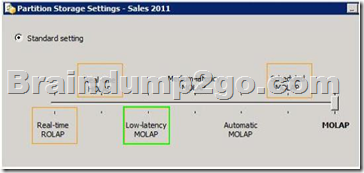
Explanation:
http://msdn.microsoft.com/en-us/library/ms175646.aspx 1
Low Latency MOLAP
Detail data and aggregations are stored in multidimensional format. The server listens for notifications of changes to the data and switches to real-time ROLAP while MOLAP objects are reprocessed in a cache. A silence interval of at least 10 seconds is required before updating the cache. There is an override interval of 10 minutes if the silence interval is not attained. Processing occurs automatically as data changes with a target latency of 30 minutes after the first change.
This setting would typically be used for a data source with frequent updates when query performance is somewhat more important than always providing the most current data. This setting automatically processes MOLAP objects whenever required after the latency interval. Performance is slower while the MOLAP objects are being reprocessed. QUESTION 21
You are designing a partitioning strategy for a large fact table in a data warehouse.
Tens of millions of new records are loaded into the data warehouse weekly, outside of business hours. Most queries are generated by reports and by cube processing.
Data is frequently queried at the day level and occasionally at the month level.
You need to partition the table to maximize the performance of queries.
What should you do? (More than one answer choice may achieve the goal. Select the BEST answer.) A. Partition the fact table by month, and compress each partition.
B. Partition the fact table by week.
C. Partition the fact table by year.
D. Partition the fact table by day, and compress each partition. Answer: D QUESTION 22
You are designing an extract, transform, load (ETL) process for loading data from a SQL Server database into a large fact table in a data warehouse each day with the prior day's sales data.
The ETL process for the fact table must meet the following requirements:
- Load new data in the shortest possible time.
- Remove data that is more than 36 months old.
- Ensure that data loads correctly.
- Minimize record locking.
- Minimize impact on the transaction log.
You need to design an ETL process that meets the requirements.
What should you do? (More than one answer choice may achieve the goal. Select the BEST answer.) A. Partition the destination fact table by date.
Insert new data directly into the fact table and delete old data directly from the fact table.
B. Partition the destination fact table by date.
Use partition switching and staging tables both to remove old data and to load new data.
C. Partition the destination fact table by customer.
Use partition switching both to remove old data and to load new data into each partition.
D. Partition the destination fact table by date.
Use partition switching and a staging table to remove old data.
Insert new data directly into the fact table. Answer: B
!!!RECOMMEND!!! 1.|2016/10 70-470 Exam Dumps (PDF & VCE) 283Q&As Download:
http://www.braindump2go.com/70-470.html
2.|2016/10 70-470 Exam Questions & Answers:
https://drive.google.com/folderview?id=0B9YP8B9sF_gNcERjZVFoYkdjTk0&usp=sharing
|